Changing how you pick your do-group
This year’s Kick-In has been different to any before it, there was no big tent, no storming of the Bastille and no large parties. However, one thing has remained the same year after year, dogroups, which are an important and much appreciated part of the Kick-In, not just for kiddos, but also for parents and associations. But not everyone is satisfied with the current dogroup system. The current ren-je-rot (run-like-hell) system has seen more than its fair share of criticism. Kiddos consistently rate this as one of the worst parts of the Kick-In, and faculties have also expressed a desire for a fairer system.
So, for years we have been thinking about ways to improve this, and in the late spring of 2019, we finally found a different and hopefully fairer manner to let kiddos pick their dogroup by letting them submit their top three favorite dogroups in our online application. The scale and impact of this change, however, would be quite a large project, not just as compared to our usual workload, but also in how much cooperation with different stakeholders was required. In this article, we want to give you some insight into how we planned and managed this transition.
Initial Pilot
The first step when introducing any transition is the validation of the chosen approach, or less abstractly, to check if your ideas align with reality. Without realizing it, our ideas were based on a fair few assumptions, not just on the applicability of our algorithm or how we had chosen to model a participant’s preferences, but even if a computer would be more fair than the previous system. Some of these assumptions were rather self-evident, for others we could clearly explain why we thought they were right. But for a small part, it would be impossible to say if we were right. We could better validate those assumptions during an actual, in-person test of the system.
However, implementing a large system like this comes at quite a cost. And if we were to choose to abandon this approach after the trial, we wanted to be able to remove it quickly and completely. So besides the earlier requirements, the system would have to be coupled in a very loose manner to the existing code-base.
During the evaluation of the system, there were several issues that had to be addressed. Some were technical, like a mistake in the selection of participants or how websocket connections were authenticated. But others were more fundamental and complex, for one it turned out that preferences should be modelled quite differently from how we had expected. But, we also saw some positive points in the evaluation. For one, the market ran smoother than any previous edition, even with all the bugs that presented themselves. But, even more encouragingly, the participants rated their experience with finding a dogroup two full points higher than their counterparts of other studies.
All in all, we were quite happy with the reception of the new system. The most important stakeholders were pleased with the improvements, and with a fair amount of changes to make, we were looking forward to the expanded trial of 2020.
Five Study Trial
This next set of trials would consist of five studies, which were selected for their comparatively small sizes. This would serve two main purposes, it would enable us to test the system at a larger scale, and it would show if the results of 2019 were universally applicable or just specific to that one study. The concern was that the improved satisfaction could just have been a fluke result. The committees of these studies participated in a project group which helped in redesigning how preferences were indicated. Instead of only providing the top three dogroups, we would now allow the participant to select which dogroups they dislike, but they can also submit a preferred type of dogroup, such as sports, culture, student association or unaffiliated.
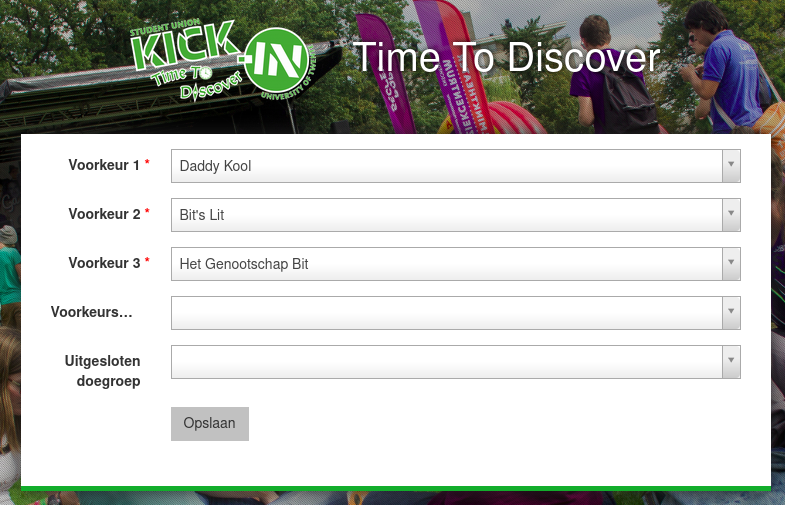
With all feedback received from the initial pilot and the project group incorporated in the new design, we were planning on implementing the updated pilot in our main infrastructure for the 2020 Kick-In. By doing this we can directly monitor whether our systems would be able to handle the increased load from not only the participants entering their preferences, but also whether the used algorithm wouldn’t use too many computational resources.
COVID-19
At the end of April it became clear that we wouldn’t have the possibility of organising the ren-je-rot dogroup market for the studies not participating in the five study trial due to the restrictions imposed by COVID-19. Required to move the dogroup markets to an online environment, we opted to directly implement the new approach for every study. Even though this might seem an obvious choice, we had some concerns about our available resources and the lack of a viable fallback method.
Full Scale Application
As the computational complexity has an approximately cubic relation with the amount of participants, we deliberately chose five small studies for the initial pilot incorporated in our existing system, but with the full scale application we would need to run the algorithm even for all large studies, while being limited in time. In order to keep the application available for other actions, we opted to limit the computation to a single study per run.
Next to the computational load, we could expect about 1500 simultaneous websocket connections waiting for the computation of their study to complete. Even though this might not seem that much, we’ve only tested our infrastructure for an estimate of 200 simultaneous connections, achieved during a ticket market where all dogroup parents would reserve tickets at the same time. Conveniently, the window during which the preferences can be submitted is not subject to limited availability and the results become available per study, which we hoped would flatten the connection curve.
Performance Impact
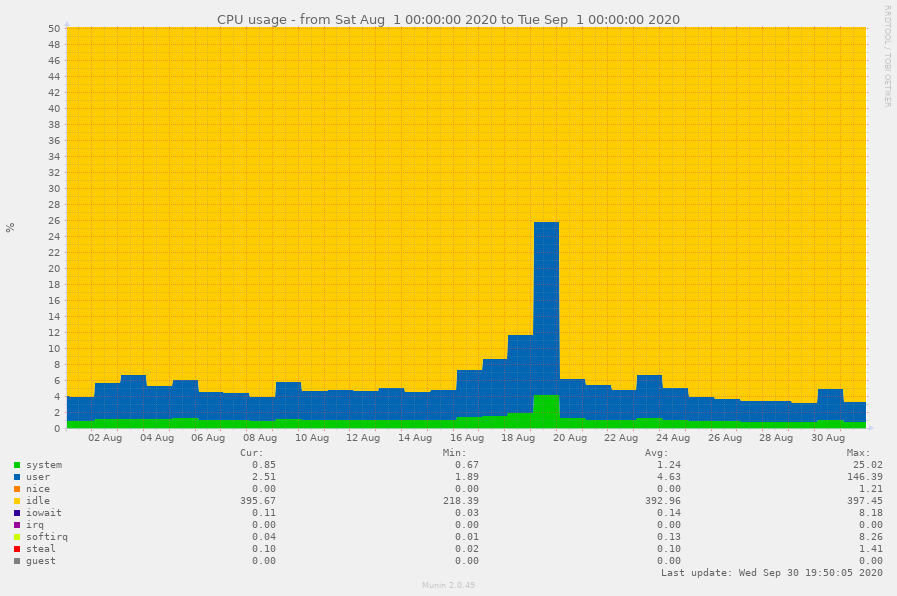
Even though we were expecting a significant performance impact and maybe even stability problems during the high load scenarios, everything completed smoother than expected. Compared with the 2019 Kick-In we did have a 2 to 3 times higher average load, depending on the type of metrics you focus on. We’ve noted about 1700 extra assured connections over the 1100 of last years Kick-In (145% increase), but on the computational load we only noted a 50% increase. Both increases did not impact our availability and seemed to be handled perfectly by our infrastructure.
Connections for the last two Kick-Ins, note that these are aggregate numbers which cannot be interpreted literally.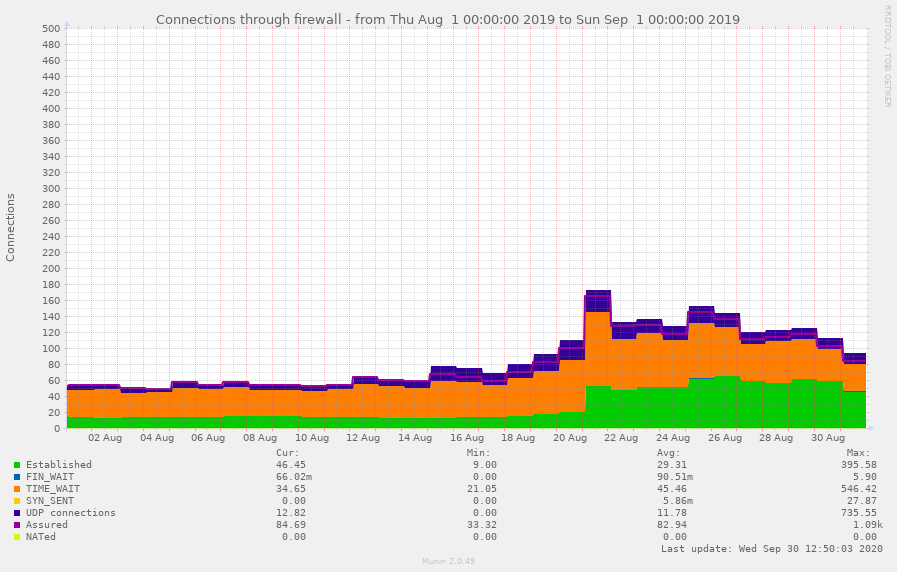
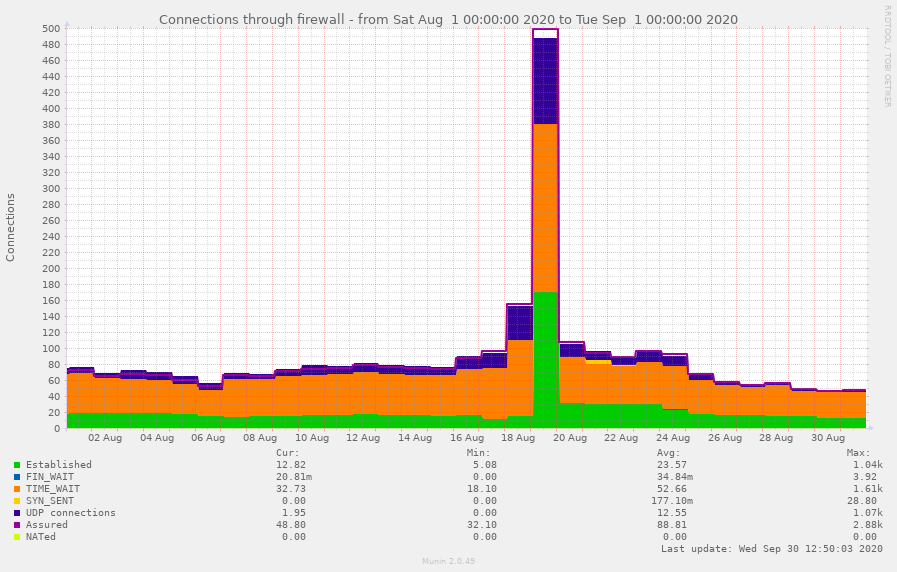
The increase difference can easily be explained: the connections are mostly from users just waiting for the dogroup assignment computation to be executed and completed, and therefore just don’t use a significant amount of computational resources. Secondly, we overestimated the impact of the algorithm on the computational load, as it completed faster then expected.
CPU usage during the last two Kick-Ins, note that the vertical axis has been enlarged.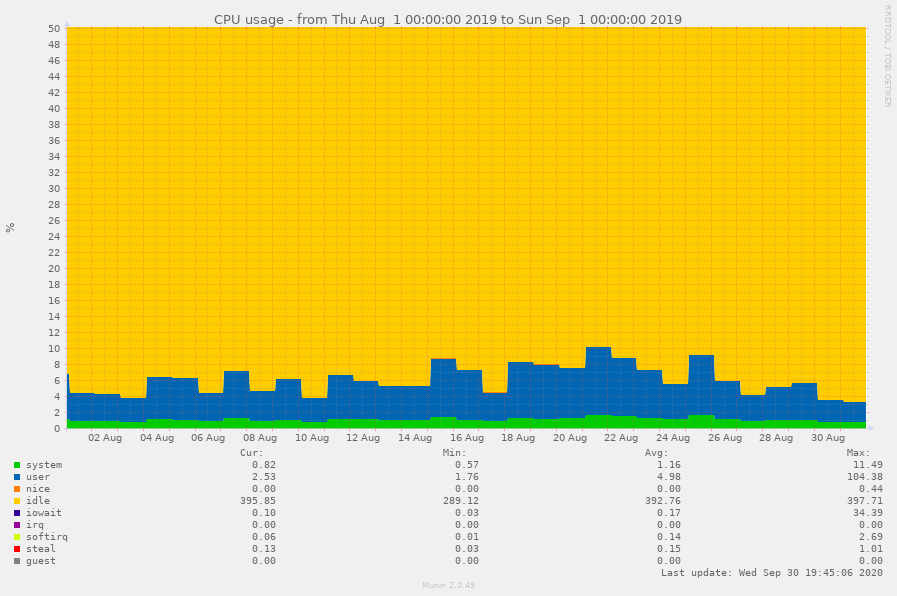
Conclusion
Introducing large changes is always a difficult process, as it is unlikely that all your assumptions will be right the first time. Certain stakeholders might even disagree on what a correct implementation of (parts of) the system should look like. Yet with proper management, and by listening to the concerns people have, a lot of trouble can be prevented, even when unforeseen scenarios such as a nation wide lockdown impose certain restrictions.
Even though the evaluation of the new dogroup market approach is not yet completed, we can already conclude that our application is capable of handling the load imposed by the algorithm and the amount of simultaneous connections. The initial feedback from the participants is also promising, but as this was indeed a year like no other we might still decide to use the old method once again next year for half of the studies, so we can properly compare both assignment approaches.
If the iDB sounds like a cool project to you and you want to help make it even better, why don’t you join us? We’re always looking for new members to implement more awesome features. If you have any questions, or want to come have a look, you can reach the iDB at idb@kick-in.nl.